Behavior
Il modulo Behavior è il motore decisionale di un'entità dinamica, progettato per operare all'interno del ciclo di
simulazione sense → plan → act.
La sua responsabilità è ricevere le letture sensoriali (SensorReadings) e produrre una intenzione, ossia l’
Action da eseguire, mantenendo una separazione netta tra la logica decisionale e l'esecuzione fisica dell'azione.
Posizionamento nel ciclo di simulazione
Il Behavior si inserisce nel ciclo di esecuzione di un'entità autonoma:
- Sense: l'entità acquisisce informazioni sull'ambiente tramite i suoi sensori, producendo un
SensorReadings; - Plan: il
Behaviorelabora il contesto e sceglie un’azione appropriata; - Act: l’azione viene passata agli attuatori, che modificano lo stato dell'entità (es. velocità delle ruote).
Nota: il behavior è stateless (decisione cieca sul tick corrente).
Se servisse “memoria”, bisognerebbe estendere il contesto di input invece di introdurre mutazioni.
I/O e contratti
Il sistema opera su dati strutturati che incapsulano tutte le informazioni necessarie:
- Input:
BehaviorContextsensorReadings: SensorReadings: le letture sensoriali correnti;rng: RNG: un generatore di numeri pseudo-casuali per comportamenti stocastici e riproducibili.
- Output una
Decision[F]ossia una funzione totaleBehaviorContext => (Action[F], RNG)(modellata come Kleisli).Action[F]: l'azione da eseguire sull'entità;RNG: lo stato aggiornato del generatore, per garantire che non venga perso il riferimento alla sequenza casuale.
Nota: un
Behaviorcompleto deve essere una funzione totale, ossia, dato un qualsiasiBehaviorContextvalido, deve sempre produrre un'Actionvalida.
Pattern Kleisli
I comportamenti sono modellati come funzioni pure da un contesto a una decisione:
Decision[F] = Kleisli[Id, BehaviorContext, (Action[F], RNG)]. Questo permette di avere:
- accesso al contesto:
Kleisli.askfornisce accesso esplicito al contesto; - composizione: con
Kleisliotteniamo combinatori (map/flatMap,andThen,local,ask) e un DSL pulito; - testabilità: si testa con
decision.run(ctx)in modo deterministico; - astrazione degli effetti: attualmente utilizziamo
Id, di conseguenza è una funziona pura; in futuro può sfruttareEither/IOsenza cambiare le API del DSL.
Astrazione dei comportamenti
Il modello si basa su quattro livelli di astrazione:
- Condition: predicati che valutano lo stato sensoriale (es. soglie/relazioni);
- PartialBehavior: regole che possono proporre
A(Some) o defers (None); - Behavior: composizione di regole con fallback garantito per assicurare totalità (sempre un’azione
A); - Policy: strategie complete e riusabili per casi d'uso specifici (es. evita ostacoli, fototassi, ecc.).
Panoramica tra Policy e Behavior
Il diagramma seguente sintetizza le relazioni tra Policy, i Behavior concreti, Decision[F] e BehaviorContext.
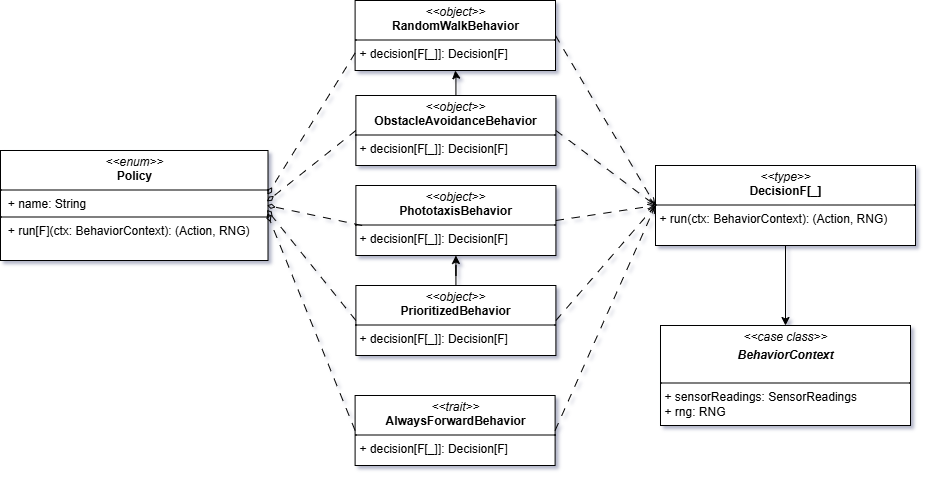
DSL di composizione
Il modulo fornisce un linguaggio specifico di dominio per comporre comportamenti in modo dichiarativo:
((front < 0.30) ==> turnRight[F]) |
((left < 0.25) ==> turnRight[F]) |
((right < 0.25) ==> turnLeft[F])
.default(moveForward[F])
Il DSL supporta:
- composizione left-biased con priorità esplicite;
- operatori logici per condizioni complesse;
- fallback garantiti per totalità.
Politiche predefinite
Sono incluse un insieme di politiche standard che coprono i casi d'uso più comuni:
| Policy | Descrizione | Caso d'uso |
|---|---|---|
| AlwaysForward | Movimento costante in avanti | Testing, comportamento base |
| RandomWalk | Esplorazione stocastica | Copertura spaziale |
| ObstacleAvoidance | Evitamento ostacoli multi-livello | Navigazione sicura |
| Phototaxis | Attrazione verso sorgenti luminose | Comportamento biologico |
| Prioritized | Composizione gerarchica di strategie | Comportamenti complessi |
Per i dettagli tecnici di implementazione, consultare la sezione implementazione behavior.